Long build times for software applications can be a significant business cost. Every minute that software developers spend waiting for the software to build is almost* pure waste. When this is multiplied across a number of developers, each running a number of builds per day, it quickly adds up.


Credit: XKCD
To make this cost more tangible, imagine an enterprise mobile app that takes 5 minutes to build. Let’s assume that there are five mobile developers in the team running an average of 24 builds per day – that’s 4 builds per hour* over 6 hours of coding time in a day. This works out to 10 hours wasted each day.
This means that if developers are paid $100/hour, a five minute build translates to $1000 per day wasted, or $5000 a week.
This is more than the cost of hiring another developer(!)
It seems likely that this cost is under-appreciated by managers. The activity of building the app is mostly invisible to them. Kicking off and waiting for builds is something developers do, most of the time.*
Since slow builds are also an opportunity for significant cost savings, this lack of visibility isn’t a good thing. If their impact is hidden from management, it’s less likely that improvement work will be prioritised, and these savings will go unrealised.
To make matters worse, there are good reasons to think that the costs (and potential savings) of slow builds are much higher than the basic calculation above suggests.
Second order effects
Earlier we assumed that one minute of build time equals one minute of lost productivity – in other words, a linear relationship. This would mean that developers become 100% productive again as soon as a build finishes, regardless of how long they spent waiting.
In reality, this is probably a gross underestimate because it ignores second-order effects. For example, most developers would probably agree that the longer they spend waiting for a build, the longer it takes to get back into a fully productive state again. The real relationship between build time and lost productivity is likely to be nonlinear – i.e. not a straight line.
Investigation
Could a more solid case be made for this theory? – that business costs increase nonlinearly with average build time?
Investigating this possibility turned up a study from Parnin and Rugaber (2010) from the Georgia Institute of Technology. They found that after a programmer is interrupted, it takes an average of 10-15 minutes for them to start editing code again. If build times past a certain length represent a kind of “interruption” (or lead to other kinds of self-interruptions) this would straight away make their cost nonlinear.
The question then becomes: how long does a build need to take before it can be considered an interruption? For example, how long before the developer’s mind starts to wander and they’re no longer in a flow state (or anything close to it)?
As a starting point we could agree that once the developer switches to another task, such as checking email or social media, they are most definitely “interrupted”.* To get a rough idea of how long it takes for this kind of thing to happen, I ran the following (very rigorous) straw poll:
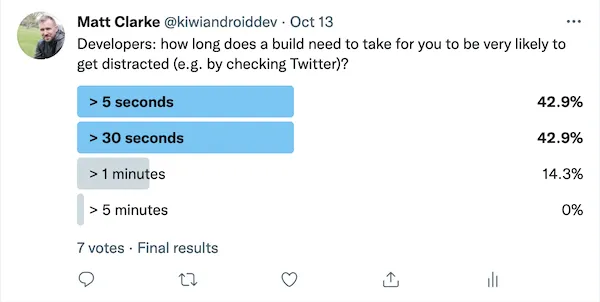
The results suggest it doesn’t take long at all. 85% of the people that responded said they are very likely to distract themselves if a build takes anywhere between 5 seconds to a minute.*
If this result is combined with the findings of a 10-15 minute cost of interruptions, a grim picture starts to emerge. Once build times exceed a certain length, their cost would jump way up.
Attempt at an improved cost model
Let’s model this with some real numbers to get a clearer picture.
We’ll call the time it takes some random developer to get distracted while waiting for a build their distraction threshold. Going by the straw poll, the distribution of these across the population of developers looks to be right-skewed. That is, most developers get distracted quite quickly, with the number quickly dwindling off from there to form a right-hand tail. By the 5 minute mark, 100% of developers are distracted.
The distraction thresholds of 10,000 random developers might look like this: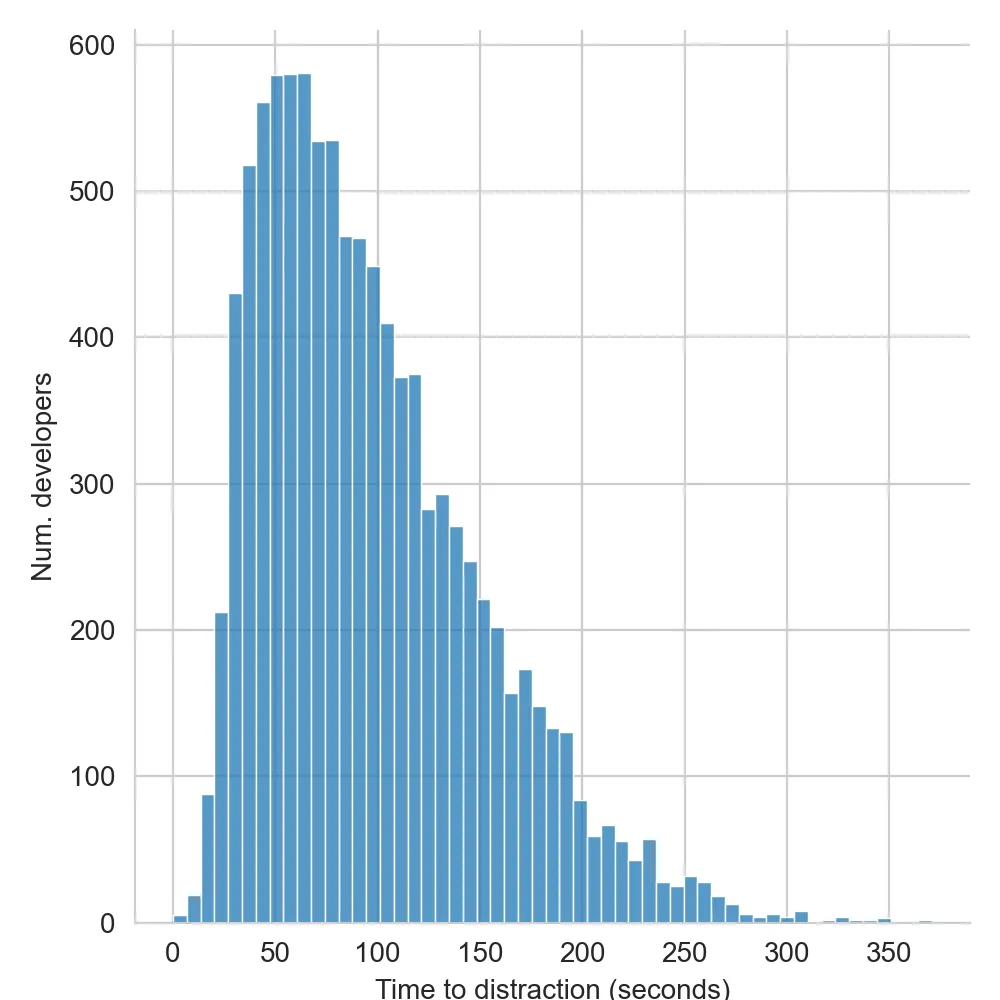
Now let’s work out how this could impact the productivity cost of build times.
To do this, let’s take the 1000 randomly generated developers from above. Then for a selection of different build times, work out the productivity cost incurred by each of them. That is, the total amount of time it takes from starting a build to being back in a productive state.
If the build time falls under the distraction threshold for a developer, we’ll assume that the productivity cost is simply the time spent waiting for the build.
However, if the build time goes above the distraction threshold, we’ll add an interruption cost on top of this. To model this extra cost we can use the findings from Parnin and Rugaber (2010). Their results on the time it takes a developer to start editing code again after resuming from an interruption (from 1,213 programming sessions) were:

Based on this table there’s a 35% chance of the interruption cost being less than one minute, and a 22% chance of it being between one and five minutes, etc.
Note that the percentages don’t add up to 100%. There’s a missing column for the 8% of sessions where the edit lag was 30-360(!) minutes.
Raw results
Running the simulation for each of the 1000 developers, and for every build duration between 0 and 5 minutes (in half second increments – e.g. 0, 0.5, 1, 1.5 seconds…), gave these results:
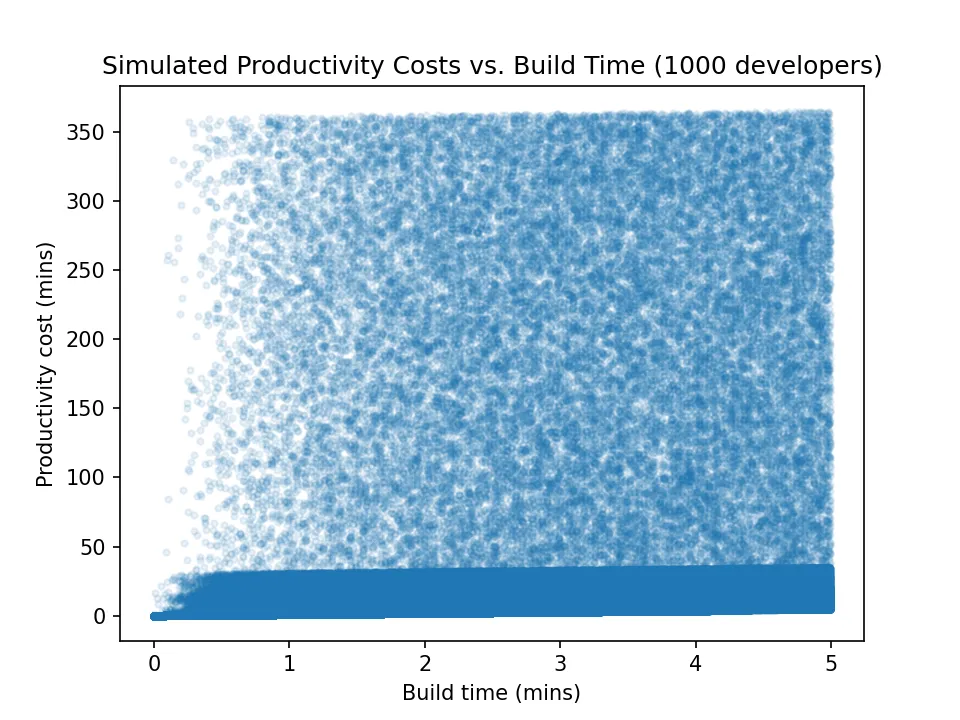
This plot is difficult to make much sense of at a glance. Most of the plot area looks to be dominated by random noise. This large noisy area is the developers incurring the full interruption cost of 30-360 minutes.
However on closer inspection, it does look this full interruption cost occurs less often in the 0-1 minute build time range – the points aren’t so dense here. This is what we would expect given the distraction threshold distribution.
Reassuringly, the high density of points falling between the 0-30 minute cost range (i.e. the solid blue band) also implies that most of the costs fall in this range.
Averaged results
Rather than plotting the raw data, we can get a clearer picture of what’s going on by only looking at the average cost incurred at each possible build time. This way we’ll have only one point to plot for each half-second, rather than 1000.
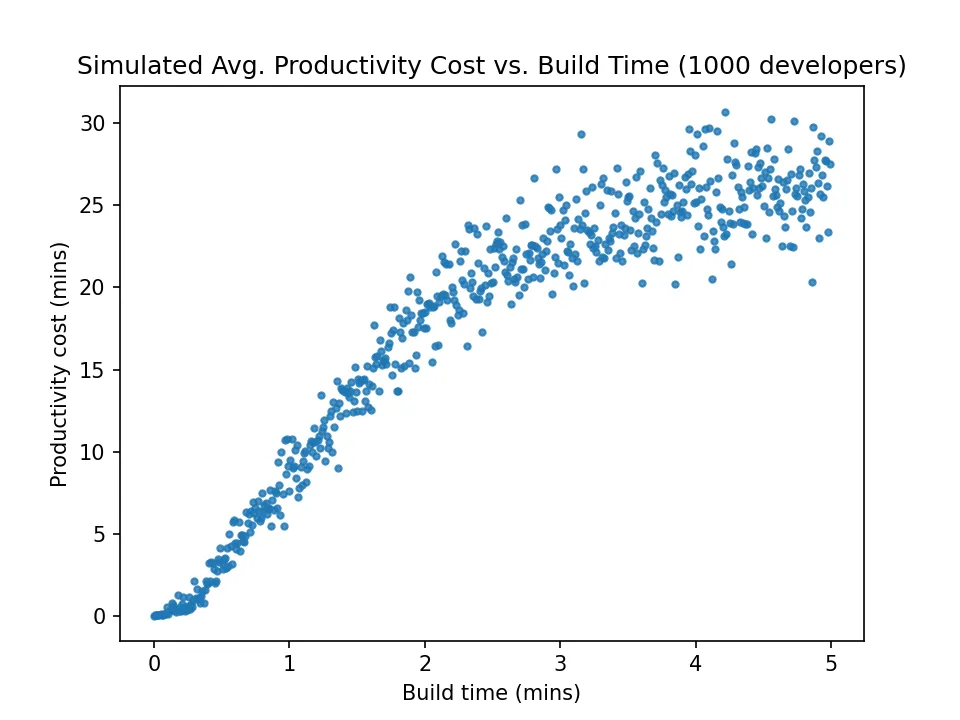
Now it’s much easier to make out a curve in the relationship between productivity cost and build time. This is even clearer if a regression line is fitted to the data:
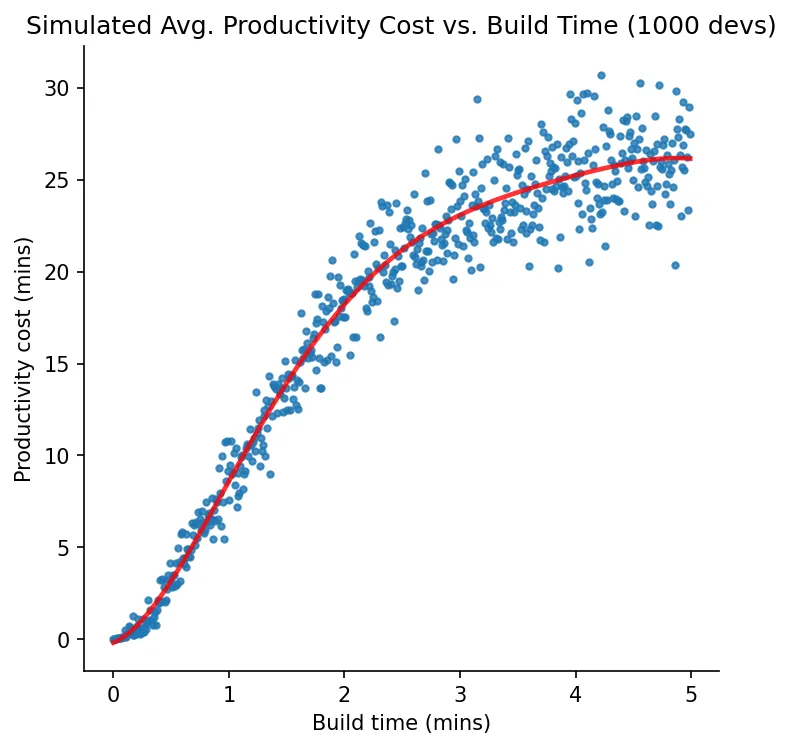
The curve appears to be S-shaped: relatively shallow and linear between 0-15 seconds, rapidly curving upwards after that, and only levelling off again around the 4 minute build time mark. The cost increases are fastest for builds about 15 seconds to 2 minutes long.
We can also see that the productivity cost becomes more variable (less predictable) as build time increases.
Business Implications
What would some of the business implications of this nonlinear relationship be? What can you take away from this if you’re managing or participating in a software development team?
On one hand, it means that slow builds probably cost a lot more than you would expect. Rather than one minute of build time equally roughly one minute of lost productivity, the real cost could be up to 8 minutes per minute of build in the worst case (the steepest part of the curve on the graph above).
The good news is that the potential cost savings are also a lot higher than you might expect. This is particularly true if the software’s build time is in the “danger zone” for developers becoming distracted – say between 30 seconds to 2 minutes long. Any investment into reducing the build time here should give disproportionate returns.
To illustrate this, assume a company’s app takes 2 minutes to build. If management decides to invest 6 developer-hours into improving the build time, and this succeeds in reducing it by only 10 seconds, this ends up saving roughly 4 minutes of productive time per build.
Plugging in some assumptions from earlier (5 developers in a team, running 24 builds a day, $100 per dev hour), this 4 minute build time saving equates to 8 developer-hours a day, or $4000 a week.
A weekly return of $4000 on a one-off investment of $600 is favorable by any measure.
It should be pointed out that builds times over the average distraction threshold (say more than 5 minutes) are likely to always incur the full interruption cost. In this zone, small improvements to the build time won’t give the same return on investment.
Via Negativa
Investment in improving build times might be attractive to product managers for another reason. Compared to other potential development tasks, it’s a low risk activity. Improving build times is generally less likely to cause unintended consequences to users compared to feature development or bug fixing work.
New feature work, while necessary to keep the product useful and competitive, can sometimes fail to pay for itself. Sometimes a new feature just falls flat with users, or even gets a negative reaction. In any case it will make the software more complex and costly to maintain.
Bug fixing work is lower-risk. But it still means changing the software’s source code, which can introduce new bugs.
Improving the build speed is relatively safer because there are many ways of doing it without changing the software’s source code. Perhaps the most obvious example of this is simply to buy faster machines. Users get the same software, it’s just built faster.
While it is true that optimizing build times can also introduce bugs, this is more true for aggressive optimizations. It’s less true for the kind of easy wins that can be gained if the build process has been a neglected area of investment.
Note that this is an example of “Via Negativa” – improvement by subtraction of the undesirable, as opposed to improvement by addition of the (assumed-to-be) desirable. Improving things by removing what’s bad is lower-risk because, as Nassim Taleb says: “we know a lot more about what is wrong than what is right.”
Limitations and Future Research
As the saying goes: “All models are wrong. Some are useful“.
With that in mind, here are some of the known ways in which this model is a simplification. These also point the way towards how further research could be done to build a more accurate model.
- The distraction threshold distribution was modelled on a survey response from 7 (probably Android) developers. Ideally a much larger sample would be used, with the distraction threshold inferred not from self-reports, but from (e.g.) analytics data from developer tools. Jetbrains could probably build a much more accurate picture from their IDE usage data.
- The model assumes that each developer has a single, unchanging distraction threshold. In reality, a developer’s distraction threshold could vary over time for any number of reasons. For example, research suggests that we’re less productive (and more distractible?) near the end of the week, after lunchtime and during winter.
- It’s assumed that developers attempt to resume their task as soon as the build finishes. In reality, it’s possible that they don’t return to development right away, but continue with the other task for a while. For example, they might finish reading the email they’re looking at first. Taking this into account would add to the interruption cost, making the current cost model a conservative estimate.
Note that there will be unknown limitations on top of these. If you notice any errors or important limitations I’ve left out, please drop me a comment below.
Conclusion
Slow build times can be a significant business expense when added up across a number of developers running multiple builds per day. If second-order effects are considered, such as the findings on interruption costs by Parnin and Rugaber (2010), the costs are greater still.
The upside of this nonlinearity is that it cuts both ways – there are significant cost savings to be had by even modest improvements to average build times. This is particularly the case when the current build time is hovering around the typical developer’s “distraction threshold” – the amount of time they wait before they’re likely to switch to another task. A straw poll indicated this could be somewhere between 5 seconds to 1 minute, however further research is needed to get a reliable estimate for this.
Thanks to Cristina and Dennis for reviewing a draft of this post.
Footnotes
- “Almost” because it’s not as though developers’ brains shut off completely while waiting for a build to finish. Assuming they don’t switch to another task, it’s reasonable to assume they’ll continuing mentally working on the task, to the degree this is possible. However, I’ve left this out of consideration to simply things.
- Note that an industry best practise for building quality software, called Test-Driven Development (TDD), prescribes rebuilding and retesting after every small change. This could be every few minutes. Therefore the cost of slow builds will be even higher for teams practising TDD. On the other hand, this should be mitigated by incremental builds, to the degree they’re supported.
- QAs, Product Owners and other stakeholders wanting the latest app version might also start builds, or at least have to wait for them. Given that this is likely to be negligible compared with the number of builds run by developers (and to keep things simple) I’ve left this out of consideration.
- Interestingly, this study from the University of Calgary found that self-interruptions (i.e. voluntary task switching) are even more disruptive than external interruptions, and also result in more errors.
- Another avenue for further research: it seems likely that the expected build time is a factor in the developer’s decision of what kind of task to switch to while they’re waiting, if they do switch tasks. E.g. if a developer knows ahead of time that the build is likely to take 10 minutes, perhaps they are more likely to visit the kitchen for a snack versus an expected build time of 10 seconds. Another nonlinearity.

