This post contains a few details on implementing a Quick Access Device Control for Android 11+. As of writing (Jan ’21), this is a relatively new feature and there aren’t many support resources out there for it. To help address this in some small part, here are a few gotchas I stumbled on while implementing it for a smart lights app I’ve been working on.
Getting Started
The first step, if you haven’t done so already, is to read through Google’s developer guide on this feature:
As far as Google’s docs go, this one isn’t too bad. It gives a overview of the most important points. However, there are some finer points it doesn’t address which you’ll most likely run into as you start to code.
With any luck, you might find answers for these in the helpful Q+A section that follows!
Q+A / Gotchas
Q: What should I put for MY_UNIQUE_DEVICE_ID? Does it need to be globally unique to prevent conflicts with device controls for other apps?
Device IDs should identify not just a type of device (e.g. “Philips Hue bulb”) but an instance of a particular device, and remain stable over time. End users add devices to the quick access section for an app, and the platform remembers which devices they’ve added using this unique device ID.
As far as I can tell device IDs are scoped to your app, so you don’t need to worry about your IDs conflicting with those from other apps. I.e. you don’t need to create some kind of fully-qualified ID including your package name.
Q: What is a template ID and why do I need to provide it?
The quick access device control API makes use of reactive streams of immutable objects to update its UI. Because of this, it needs a way of identifying a particular template over time, independent of its object identity. This is where the template ID comes in. It lets the platform code know that two template objects with different properties (say a different title or range value) are actually referring to the same UI widget if their template IDs match.
Q: How should a communication error with my device by signaled back from performControlAction()? Via the existingPublisher for the device or the Consumer<Int> parameter?
Via publisher. The Consumer parameter is just for signalling that the control action was received successfully, not necessarily that it was delivered to the device.
Q: How do I know when it’s safe to disconnect from the device or cleanup other resources?
Add a doOnCancel()listener to the Flowable returned by createPublisherFor(). It will be called when the Quick Access Device Controls UI goes to the background.
I was recently exposed to the idea of Non-Fungible Tokens (NFTs) through Twitter. I’ve struggled to wrap my head around them ever since. What does it mean that people are willing to pay millions to own a Tweet or JPEG? How does that sentence make any sense? And why do the concept of NFTs reliably evoke such polarised emotional reactions?
There was a recent article featured on Hacker News titled NFTs Are a Dangerous Trap. This was useful, but perhaps more for the comments it generated than for the article itself. The comments represented a wide range of perspectives, often passionately and intelligently argued for. Like the parable of the Blind men and the Elephant, it’s useful to listen to a number of voices when something new and mysterious is encountered. Each one might have a grasp of part of the truth. It’s also possible the new thing is in fact many things all at once.
The Blind men and the Elephant
After some reading and thinking, the conclusion I started to come to was that NFTs aren’t hard to grasp for technical reasons – at least not primarily.
Rather, NFTs are hard to grasp mostly because of the strangeness of the more fundamental ideas they rest upon – ideas like ownership and value. These are ideas that have, until recently, been easy not think too much about. NFTs have changed this by being so difficult to ignore.
Is Ownership Real?
To test this theory, let’s forget about NFTs for a second.
What does it mean to “own something”, really? How does the concept of ownership map onto the objective, material world, if at all? When you get down to it, does owning something just mean the ability to defend access to it through the threat of physical force? It could be you, your family, friends, hired guards or the state that wields this force. In any case, it’s hard to imagine ownership would count for much if it couldn’t ultimately be enforced physically.
It could be argued that direct, physical force isn’t needed to enforce ownership. Imagine children playing the board game Monopoly. If one child openly steals the other’s Monopoly money, the other children will soon refuse to play with him. Social exclusion is really painful; it appears to activate the same areas of the brain as physical pain [1]. This makes a lot of sense from an evolutionary perspective. Exclusion from the social group means a lower chance of survival and of finding a mate. Direct physical force might be more obvious and easier to observe, but the effect is the same in both cases – pain, potential harm and death.
So on one hand ownership is “merely” an abstract concept, a social contract that we act out. It’s not something concrete you could point to in the external world. On the other hand, violating it leads to undeniably real and painful consequences. Given this, is it so unreasonable to act as if it were just as real as something you could feel, smell, taste or see (to quote Morpheus)?
Is Value Purely Subjective?
Another, equally mysterious topic rudely forced onto us by the arrival of NFTs is that of value. What makes something valuable? Is this value “real” or something purely subjective, reliant on collective whim, at risk of evaporating at any moment? If so, is this true of everything valued? Or are some things really, intrinsically valuable, independent of anyone’s opinion?
I suspect these questions are difficult because they can’t be easily reconciled with a scientific, materialist view of reality – the dominant view of our culture. They would sound absurd to someone from a pre-scientific time. “Of course those shining gold bars are really valuable. Just look at them.”
To borrow an example, imagine Elvis Presley’s guitar. It is functionally identical to thousands of other guitars like it, yet it is far more valuable. Is this value “real”? If it is, it can’t be due to the physical properties of the object itself. Its value isn’t intrinsic to the object, much like how paper money isn’t intrinsically valuable. You can’t do anything with it that you couldn’t do just as well with any other guitar (from a narrow, utilitarian perspective at least).
Is it valuable then merely because enough other people agree that it is? Then how does this agreement come about?
There seems to be some relationship between an item’s uniqueness or rarity and its value. Could this be the reliable, objective foundation on which broad agreement on value rests? There was only one Elvis Presley and that was the one (generic, mass-produced) guitar he played.
However, on further inspection this uniqueness/rarity theory doesn’t hold up. Why? Because the same could be said about any second-hand guitar – that it was once owned by a unique person. Only, say, John Doe from down the street instead of Elvis.
So being associated with a unique individual isn’t enough, there’s more going on here. An obvious omission is that Elvis is widely recognised as an important figure in popular culture, unlike John Doe (in Western culture at least – more on this soon). Why does this matter though? Why does this mean that more people would be willing to expend more hours of their labour to own his guitar? Perhaps because there are many more people with a positive emotional connection to Elvis and his music – his guitar has sentimental value for them. Seeing Elvis’ guitar hanging up in their house would make them smile and feel a sense of pride. It would also reliably communicate something to others and themselves about their identity.
You could go further still and make the case that the new guitar owner’s positive emotions are due to their increased social status. This increase in status translates to increased survival and reproductive opportunities, etc. Though perhaps this isn’t necessary; it’s enough to simply recognise that the expectation of positive emotions and a buffering of one’s sense of identity are part of what makes something valuable.
Are iPhones Intrinsically Valuable?
Earlier I said that Elvis is widely recognised as a important figure in Western culture at least. Conversely, it’s not hard to imagine a remote, isolated culture where Elvis is unknown and his guitar has no use other than as firewood. The same is true of objects we might think of as having “intrinsic” value – a BMW or an iPhone let’s say. Move these objects to somewhere without electricity, gas and internet access and they become basically worthless. So their “intrinsic value” is revealed to be nothing of the sort. The value of an iPhone is just as contingent and dependent on a particular context as Elvis’ guitar.
So is there anything with intrinsic and objective value, that is valuable for all people at all times – past, present and future? What about food? This is more of a stretch, but it’s not impossible to imagine a future where Elon Musk’s Neuralink reaches the point where it’s possible for us to transplant our consciousness into a machine. Food as we know it today would then be worthless.
Where Two Worlds Meet
It’s as if the question of value has no bottom. The more you think about it, the more questions are raised and the more mysterious it becomes. It’s indefinitely deep. NFTs have opened Pandora’s Box, and the mysterious nature of value is one of its contents.
To repeat, I suspect such questions are difficult to us because they can’t be easily reconciled with a purely scientific, materialist worldview. In order to objectively explain events in an independently-reproducible way, it’s necessary to eliminate the subjective human experience from consideration as much as possible. This is by design, and is necessary for science to function.
But try to measure the value of a guitar from an objective standpoint – it’s not possible. Any question of value must involve a subject. And while an item’s value isn’t objective, it cannot be easily dismissed as “merely subjective” and therefore irrelevant. The value of a stack of papers with pictures of the Queen might not be observable or measurable in a lab, but try throwing it into a crowd. Their resulting behaviour will most definitely be independently observable, measurable – and relevant to a living person.
A final leap of wild speculation. Could it be that NFTs have done nothing less than expose a place where the objective and subjective (or concrete and abstract) worlds meet, showing them to be part of the same world, not quite so distinct and irreconcilable after all? And all in a way that’s difficult to ignore.
It’s interesting how learning is sometimes like travel. At the end of the journey, you end up back where you started, only with a broadened perspective.
Trivial example: code comments. As a new programmer, I commented my code extensively. This was probably to compensate for my difficulties in reading code. It also allowed me to be lazy in the code I wrote. There isn’t as much of a need for clear and readable code when there are always plain English comments to fall back on.
Then I joined a team that was militantly against comments. Every comment was an admission of a failure to write readable code. I took this on-board and disciplined myself not to rely on comments. This forced me to spend more time on refactoring my code to make it as readable and “self-documenting” as possible. I still wouldn’t say I’m there yet, but I’m confident that my code is much more readable now than it was then.
However, in the last year or so, I’ve started adding comments again. Not too many, but here and there to add more context. It felt like blasphemy at first. Some of my comments are even somewhat redundant, but I’ve since learned that encoding the same information in redundant ways aids comprehension. For example, traffic lights use both colour and position to encode the same information.
Superficially it seems as though I’ve returned to where I started: I’m commenting code again. However, if I hadn’t disciplined myself to do without comments for a while, I wouldn’t have been forced to learn how to write more readable code. Abstaining from code comments is a forcing function for more readable code. At some point, you can re-integrate commenting as a useful tool rather than a crutch.
Interestingly, I’m confident that if I could travel back in time and tell past-me or any of my old teammates that, actually, comments can be a valuable tool to aid comprehension, I’m positive I would encounter strong resistance. This is just as it should be; I don’t think it can be any different. When you’re learning a new skill, it’s necessary to become somewhat closed off and follow a direction single-mindedly for a while. It’s part of the learning process. If you were too suggestible and deviated too easily, you would go around in small circles and never get anywhere.
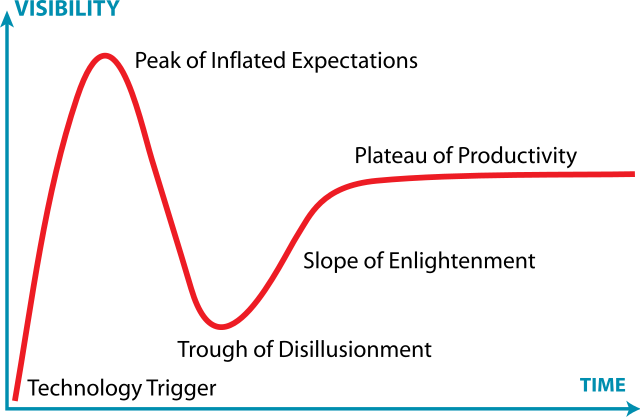
You see the same pattern across the development community when a new technology or framework is introduced (I won’t name names. I’m sure you can think of some examples). In the early days, there is hype and zealotry. Then over time as more developers adopt the tech into production and real issues with it emerge, there is disillusionment and abandonment. Finally a more realistic, calibrated picture of the trade-offs of the technology emerge.
To show a specific selection of your posts in the sidebar, contrary to what some top-ranking search results will tell you, you don’t need to install yet another spammy WP plugin or write any HTML.
All you need is the standard Text widget.
Here’s how to add your own “selected posts” section.
Steps:
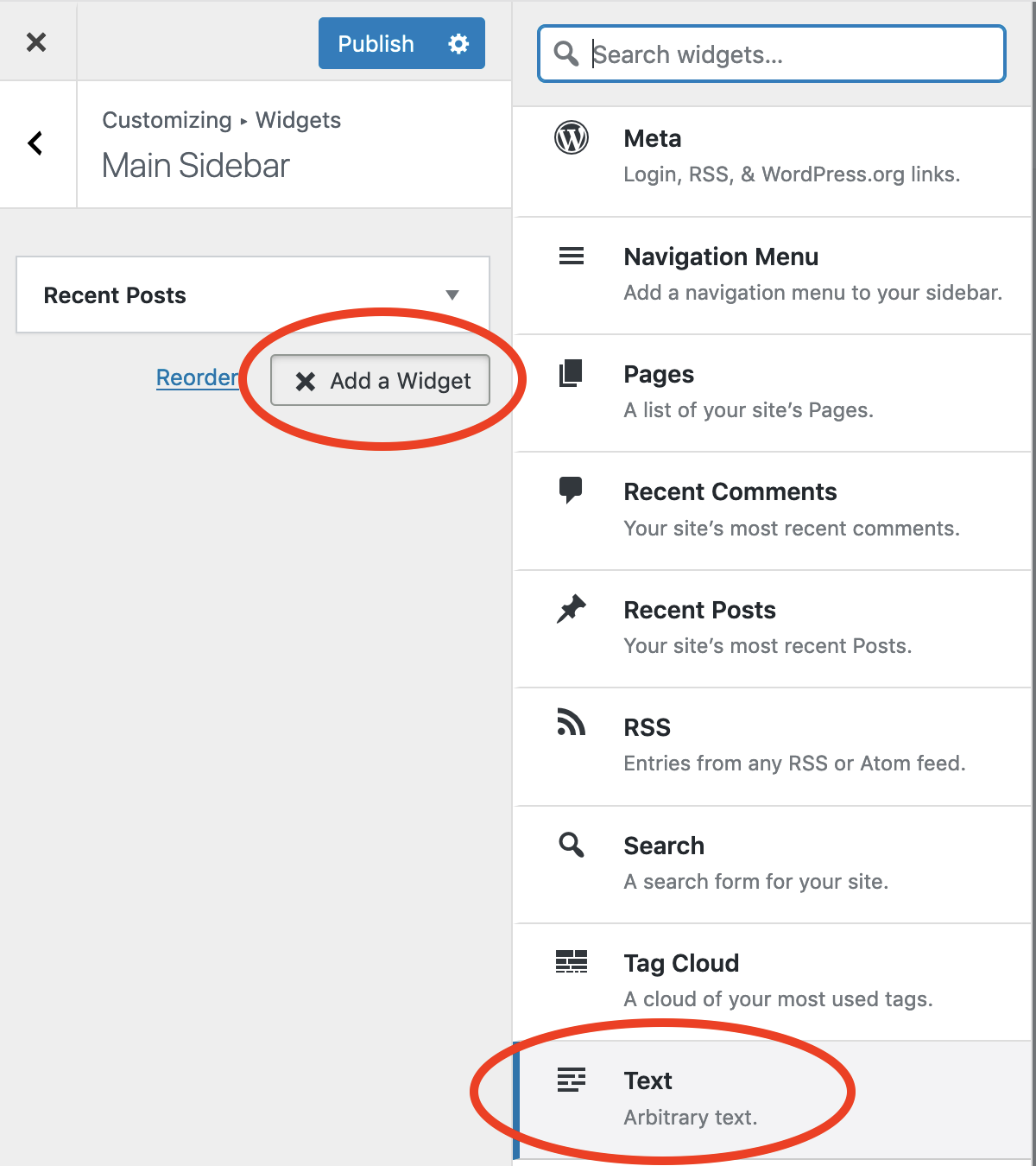
Go to Dashboard >Appearance > Customize
Click Widgets > Main Sidebar (this part may vary depending on your theme. I’m using currently Astra)
Click Add a Widget then “Text – Arbitrary text”:
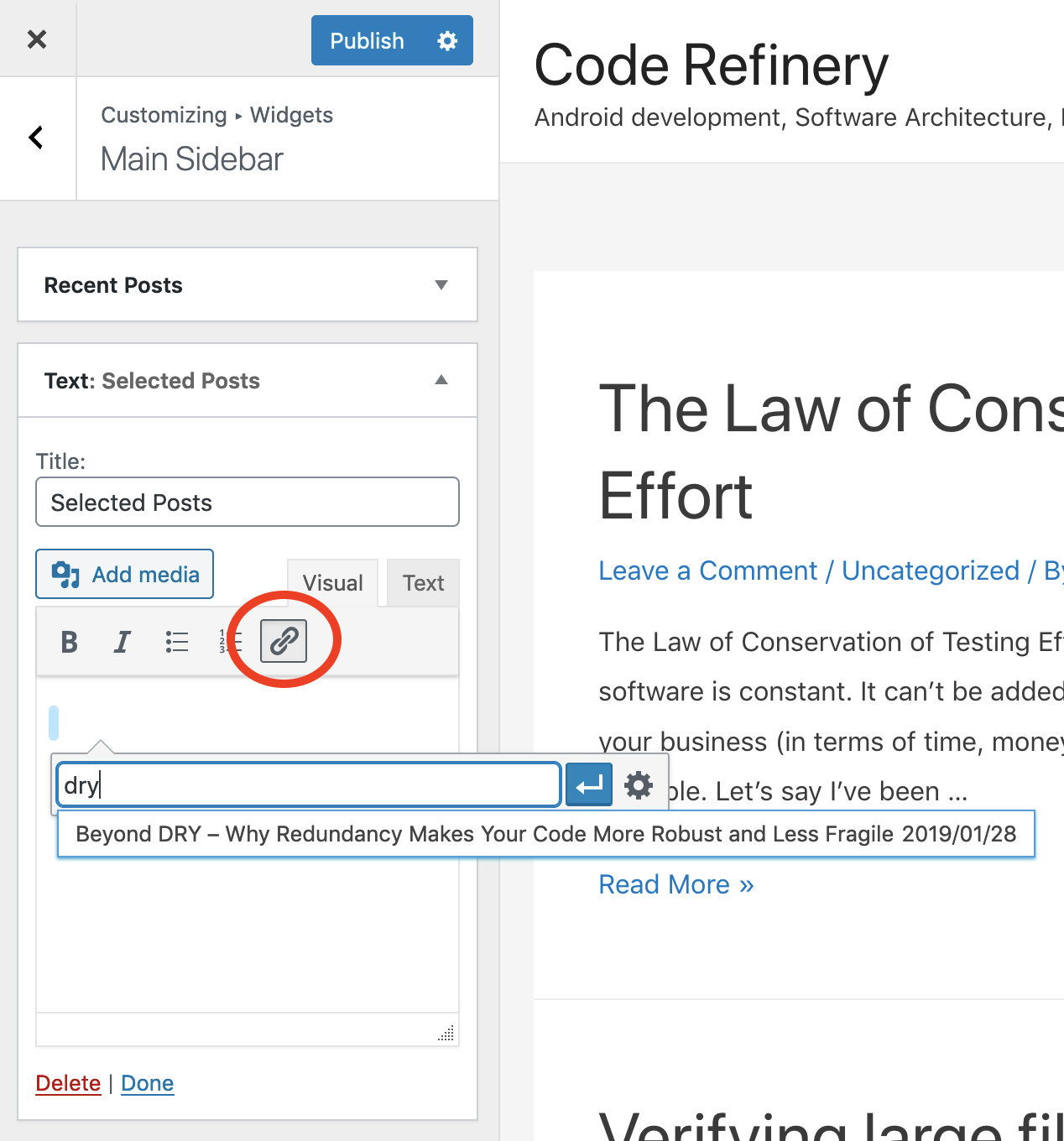
Enter “Selected Posts” for the widget title, or something similar
To add posts, click Insert/edit link then start typing the title of one of your posts. WordPress will auto-suggest matching posts in a drop-down list.
Note: you can customize the link titles in case the default ones include odd formatting characters.
When you’re done hit Publish.
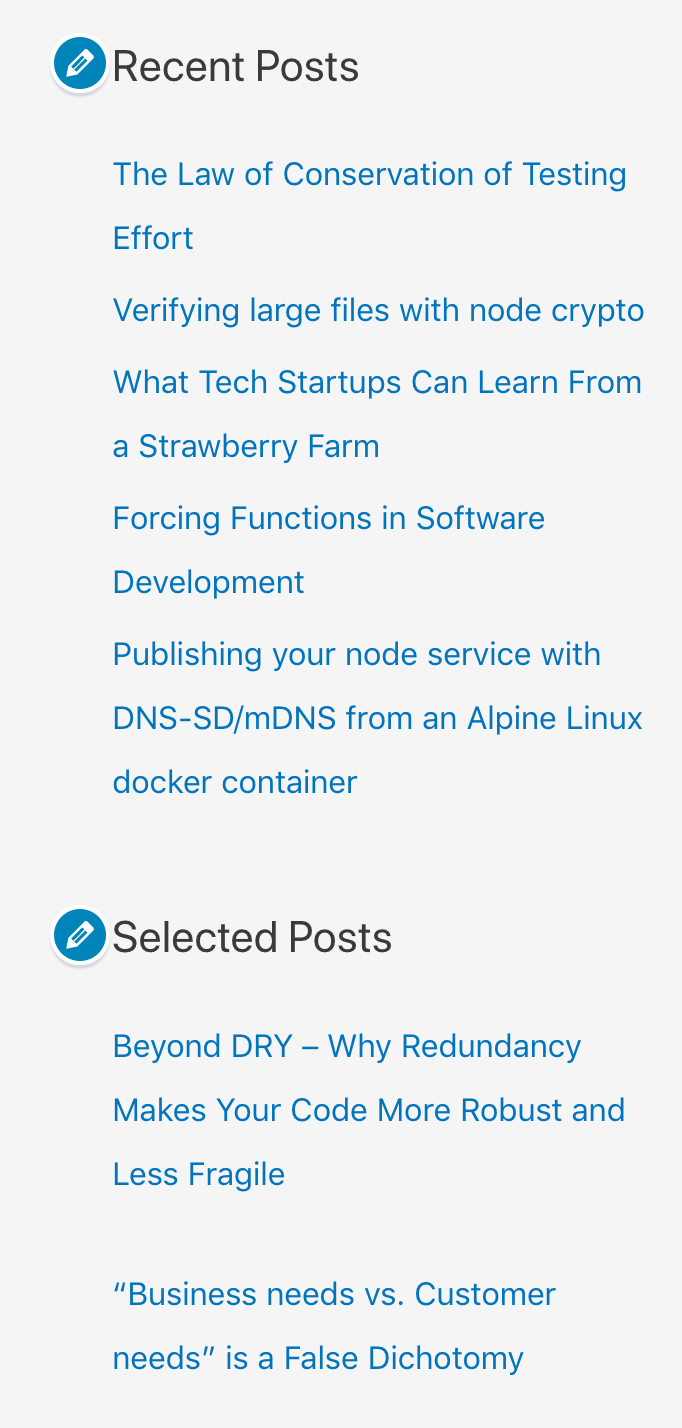
The style of the final result should match your Recent Posts widget (if you have one) exactly:
I hope this is of some use. WordPress has a thriving ecosystem of plugins but many of them are spammy at best, predatory at worst, and (in this case) completely unnecessary.
Like energy, the total testing burden for a piece of software is constant. It can’t be added to nor reduced, only transformed.
However, the cost to your business (in terms of time, money and trust) of these different forms is variable.
Here’s an example.
Let’s say I’ve been tasked with adding a new screen to my company’s mobile app. Let’s also say I’m not in the mood for following TDD right now. I just want to see the new screen in the app as soon as possible.
So I go ahead and write the feature without any tests.
Since I’m still somewhat of a responsible developer, I realize I need to test the scenarios for the new screen before shipping it. It’s just that now I have to test them manually.
Luckily, everything works the first time. Nice. I just cleverly avoided spending an extra hour of tedious development time writing tests.
Or did I?
Notice that I didn’t actually dodge any testing responsibilities. I simply exchanged up-front, deterministic, slow-to-write, fast-to-run tests for after-the-fact, non-deterministic, free-to-write, slow-to-run tests. This seems like a good deal if I only need to run the tests once.
In reality, software always needs changing. Software that doesn’t change is obsolete, or soon will be, almost by definition. So changes to my new screen will inevitably be needed. And with every change, the tests need to be run again, and the prospect of doing them manually becomes less and less attractive. This shifts the cost-benefit equation in favour of the up-front, automated tests.
Let’s say I’m a less responsible yet even more confident developer (not a good combo). After coding the new screen, I just give it a quick smoke test. The screen shows up with the expected content. Nice. Ship it. I go and get a coffee, satisfied with my speed and skill as a developer, having cleverly dodged both automated testing and manual testing.
What about the burden of testing the different edge cases for the new feature? Did it evaporate? No, it was merely shifted onto the users – unbeknownst to them. The testing effort remains constant but the cost has changed. The immediate, measurable cost of developer time is exchanged for a delayed, less-measurable cost to your product and company’s reputation – i.e. lost trust with your users as they discover bugs that could have easily been found prior to shipping. It’s not hard to see how this will ultimately impact your company’s bottom line.
Now, am I making the case that you should work to predict all possible errors for all conceivable scenarios before shipping anything? Not at all. Due to the ultimately unpredictable complexity of a real production environment with real users, there is a class of errors which you can only find out about by shipping. Some of the testing burden forever rests on your users.
Also, too much time spent trying to predict errors comes with its own costs. As Charity Majors points out in her article I test in prod:
80 percent of the bugs are caught with 20 percent of the effort, and after that you get sharply diminishing returns.
Failing to ship fast enough deprives your users of valuable-but-imperfect software and deprives your team of valuable learning. This learning is absolutely crucial in adapting the product quickly enough for the business to survive.
The implication of the Law of Conservation of Testing Effort is not that all testing should be done before production. It’s that attempting to dodge the kinds of testing more appropriate to pre-production merely shifts the burden into post-prod, where it costs more.
The phrase “I don’t always test, but when I do, I test in production” seems to insinuate that you can only do one or the other: test before production or test in production. But that’s a false dichotomy. All responsible teams perform both kinds of tests. [Emphasis mine]
Multicast DNS service discovery, aka. Zeroconf or Bonjour, is a useful means of making your node app (e.g. multiplayer game or IoT project) easily discoverable to clients on the same local network.
The node_mdns module worked out-of-the-box on my Mac. Unfortunately things weren’t as straightforward on a node-alpine docker container running on Raspberry Pi Zero, evidenced by this error at runtime:
Error: dns service error: unknown
at new Browser (/home/app/node_modules/mdns/lib/browser.js:86:10)
at Object.create [as createBrowser] (/home/app/node_modules/mdns/lib/browser.js:114:10)
Here’s how I managed to solve this. The following was pieced together from a number of sources (linked at the end).
I’ll assume you have a node app using node_mdns to publish your service, and a Dockerfile based on alpine-linux to build your app into an image for running on the Pi.
Firstly, you’ll need to have the alpine packages to run the avahi daemon, along with its development headers and compat support for bonjour. I.e. in your Dockerfile:
FROM arm32v6/node:10-alpine3.9
# Avahi is for DNS-SD broadcasting on the local network; DBUS is how Avahi communicates with clients
RUN apk add python make gcc libc-dev g++ linux-headers dbus avahi avahi-dev avahi-compat-libdns_sd
You’ll need to make sure the DBus and Avahi daemons are started in your container before starting your node app. Since you can only execute a single startup command from your Dockerfile, we’ll need to bundle the commands into a startup script, and run that. In your Dockerfile:
ENTRYPOINT ["./startup.sh"]
And startup.sh:
#!/usr/bin/env sh
dbus-daemon --system
avahi-daemon --no-chroot &
node index.js # your app script here
Note: --no-chroot is added to avoid this runtime error:
alpine linux netlink.c: send(): Not supported
Build your Docker image (since this is for a Pi Zero in my case, I’m using DockerX to build for the ARMv6 architecture on my Mac. I recommend this over waiting days or weeks for it to build on the Pi Zero):
Now push then pull your Docker image onto your Raspberry Pi. If you don’t want to use a cloud-hosted registry, I’d recommend taking a look into setting up a local registry to push it directly to the Pi on your local network.
To run your docker image on the Pi, you’ll first need to disable the host OS’s avahi-daemon (if any) to prevent conflicts with the avahi-daemon that will be running inside your alpine-linux container. On Raspbian, you can disable avahi with:
# SSH into your Pi
sudo systemctl disable avahi-daemon
Then to run your docker image:
docker run -d --net=host localhost:5000/myapp
(localhost:5000 here refers to a local docker registry.) Using the host’s network (--net=host) seems to be necessary for mDNS advertisements to function. In theory you should be able to just map port 5353/udp from the container, but this didn’t work. (If you happen to know why, please drop a comment below).
That’s it. If all goes well you should be able to see your service advertised on the local network. E.g. from a Mac on the same network (the last line is our node app’s http service):
“We have to balance the customer’s needs with the business needs”.
How many times have you heard this while working in a software development team?
I’ve worked as a mobile developer at a number of large companies. In enterprise environments like these, typically the mobile app is “the storefront of the business”, and brings together a number of features paid for by other departments.
Often the initial requirements from the other department will come with a suggestion to make their feature more prominent in the app. For example, “add it to the top of the dashboard”, “just add a new tab for it” or “send a push notification to our users about it”.
This is understandable. The job of the people from the other department is firstly to improve the area of the business they are responsible for. Their job is not to work out how to nicely integrate their feature into the app so it plays nicely with every other feature. That’s the app team’s job.
When members of the app team point out that adding a new top-level tab or push-notification for every new feature requested by every department isn’t a sustainable long-term strategy, and will lead to a poor user experience, the protest that often comes back is something like:
Well, we have to remember to balance the customer’s needs with the business needs.
I was never comfortable with this statement. It’s taken me a while to think through exactly why this is. What I eventually concluded is that while it seems reasonable on the surface, buried in it is a wrong assumption.
It’s not that you should always prioritize the customer’s needs over business needs, or vice versa. Rather, the assumption underlying the statement – that these two things are at odds – is wrong. It’s a false dichotomy.
To believe that “balancing the user’s needs with business needs” makes sense, you need to be engaged in short-term thinking of one kind or another.
If you want your business to survive in the long term, there can be no distinction between the interests of your customer and those of your business.
Your business exists to serve a customer, in a sustainable way. In the final analysis (assuming a free market where your customers can leave), business needs and customer needs must be aligned. Promoting one at the expense of the other actually harms both.
Likewise, building a system that helps your customers at the expense of the business is actually harming both your customers and the business.
How does this second point make sense? I.e. how is that helping your customers at the expense of the business actually harms them?
Here’s how: presumably, your customers would rather your business continues to exist than not. For example, bribing customers with giveaways and subsidized prices isn’t sustainable. If you “spend 1 dollar to make 80 cents”, you will eventually go out of business.
When this happens, you will (at the very least) inconvenience your customers, leaving them bereft or forced against their wishes to switch to a competitor. Or if you offer something unique, you deprive them of that unique offering altogether.
Is it idealistic or wishful thinking to see the success of your customer and business as inextricably linked? Jeff Bezos, the CEO of Amazon, doesn’t seem to think so. The top 3 of his 4 pillars of Amazon’s success are:
Customer Obsession
Eagerness to Invent to Please the Customer
Long-term Orientation
So next time you hear that the “needs of customer need to be balanced with the needs of the business” remember that to successful businesses, there is really no distinction.
Thanks to Xiao and Arun for their feedback and suggestions. Liked this article? Please consider sharing it with your friends and colleagues with one of the buttons below.
Anti-Fragile by Nassim Nicholas Taleb is a goldmine of practical ideas for software developers, despite it not being a software development book.
Redundancy is one example of such an idea that is explored. Taleb explains how having some redundancy reduces fragility, and means we don’t need to predict the future so well. Think of food stored in your basement, or cash under your mattress.
Taleb notes how nature’s designs frequently employ redundancy (“Nature likes to overinsure itself”):
“Layers of redundancy are the central risk management property of natural systems. We humans have two kidneys […] extra spare parts, and extra capacity in many, many things (say, lungs, neural system, arterial apparatus), while human design tends to be spare and inversely redundant, so to speak – we have a historical track record of engaging in debt, which is the opposite of redundancy”
Software source code is a good example of human design that tends to be “spare” (having no excess fat) and “inversely redundant”. Redundancy in code is traditionally avoided at all costs. In fact, one of the first principles that junior developers are often taught is the DRY principle – Don’t Repeat Yourself. As far as DRY is concerned, redundant code is a blight that should be eliminated wherever it shows up.
There are good reasons for the DRY principle. Duplicate code adds noise to the project, making it harder to understand without adding any obvious value. It makes the project harder to modify because the same code must be maintained separately at each place it is duplicated. Each of these locations is also another opportunity to introduce bugs. Duplicate code feels like waste.
However, as Taleb states:
“Redundancy is ambiguous because it seems like a waste if nothing unusual happens. Except that something unusual happens – usually.” [emphasis added]
What are these “unusual things that usually happen” in software development? And how could duplicate code possibly help protect us against them?
The Wrong Abstraction
Firstly, remember that duplication is eliminated by introducing abstractions, such as a function or class. The problem with abstractions is that it is difficult to know ahead of time whether a chosen abstraction is actually a good fit for your project. And the cost of getting this wrong is high. Poorly-chosen abstractions add friction to making the kinds of changes that are actually needed for the project, while still exacting an ongoing cost in terms of complexity. There’s also the risk that by the time poor abstractions have been recognised as such, they have already spread throughout the project. Rooting them out at this point will likewise impact code all throughout the project, potentially with unintended consequences.
The “unusual things that usually happen” in software development are unexpected, unpredictable (and unavoidable) changes in business requirements. These have the annoying effect of revealing the shortcomings of your abstractions, abstractions that you perhaps added while faithfully following the DRY principle.
Too-eager abstraction and a lack of redundancy mirrors the problems of centralisation, another idea explored in Anti-Fragile. Centralisation, while efficient in the short-term (read: less code), makes systems fragile. When blow-ups happen, they can take down (or at least damage) the entire system. NNT outlines in Anti-Fragile how such fragility and lack of redundancy was the cause of the banking system collapse of 2008.
Redundancy in the form of duplicated code, on the other hand, makes code more robust. It does this by avoiding the worse evil of introducing the wrong abstraction. In this way, it limits the impact of unexpected changes in business requirements. As Sandi Metz states: “Duplication is far cheaper than the wrong abstraction”
The Rule of Three
As it turns out, there is another software development principle (or rule of thumb) which does recognise the risks of poor abstractions, and seeks to mitigate them through some redundancy. It’s called the “Rule of Three”. It states that you should wait until a piece of code appears three times before abstracting it out. (Note that this appears to contradict the DRY principle). This minimises the chances that the abstraction is premature, and increases the chances that it addresses a real, recurring feature of the problem domain that is worth the cost of abstraction.
Introducing an abstraction is in some sense a prediction of the future. Abstractions make a certain class of future changes easier, at the cost of some extra complexity and fragility. They are worth this cost if and only if the types of changes they make easier actually turn out to be reasonably common. Following The Rule of Three means deliberately holding off on making a prediction until more evidence has come in. The assumption built into the Rule of Three is that past changes are the best predictor of future changes.
Back to Nature
Now to return to Taleb’s observation of widespread redundancy in nature’s designs. An interesting implication of this is that despite all of the apparent “waste” involved, evolutionary processes have nonetheless converged onto it as the best strategy for dealing with unpredictability – a permanent feature of the real world (or at least, a better strategy than no redundancy – having one kidney, for instance).
At a high level, our software projects and teams are similar in the sense that they exist in a challenging, competitive environment punctuated by unpredictable changes. If meaningful parallels can be made between complex systems, it’s worth considering the possibility that despite the apparent “waste” involved, some redundancy is likewise the best strategy for dealing with the unpredictability in our environment too.
This is all to say: go forth and fearlessly copy-paste more code 🙂
Last month I was fortunate enough to spend two weeks traveling around southern China including Hainan, Guangzhou, Macau and Hong Kong. It was an awesome trip; I would particularly recommend stopping by Hong Kong for a few days to check it out if you get the chance. It’s an amazing, vibrant city.
At some point during the trip I started noting down the things I was learning (about travel in general, and travel around cities in particular) into Evernote. Over time the list kept growing. What follows is an edited version of the original list, compiled into a top 10 (in typical web article fashion…)
1. Get the phone number of contacts in foreign country
If you’re meeting friends at the destination airport, make sure you have their mobile number. Just having them on Google Hangouts, WeChat, Facebook messenger or <insert online service here> won’t cut it as you can’t rely on WiFi access at airports. In Shanghai for example, you’ll still need a local mobile number to access the “Free” airport wifi.
Old fashioned and low-tech is sometimes best.
2. Double check that airports of connecting flights match
Cities can have more than one airport, and they may not be close together at all. As a New Zealander, this was surprising to learn…
3. Bring plenty of cash in the local currency
Unlike credit card and bank cards, cash is guaranteed to be accepted everywhere and is a lifesaver in emergencies.
Even if you’re going to a first-world country, don’t assume your card will be widely accepted, even at popular tourist attractions. For instance, you’ll need cash to buy a ticket for the Victoria Peak Tram in Hong Kong.
Another tip: divide your cash up and distribute it amongst your bags. That way if one goes missing, you still have backups. I had three stashes: one in my checked-in luggage, one in my backpack and a small amount in my wallet.
Again, low-tech = good.
4. Pack the night before
It’s easy to be unrealistic about how easy and fast it will be to “throw everything into your bag in the morning”. If checking out of your hotel room in the morning, do all possible packing the night before.
5. Invest in good walking shoes
When you’re out exploring all day every day, decent shoes will really pay dividends. Conversely, bad shoes and feet that are killing you each day can put a damper on your travel experience!
6. Sort out mobile data for your smartphone
Having internet access on your smartphone is absolutely essential when travelling, if only for Maps/GPS, Google Translate and being able to research other places to see while you’re already out.
With that in mind, set up global roaming with your mobile provider before you leave, or check if SIM cards are freely available at destination country. Some countries require you to be a local resident and/or have identification to get a SIM card (Hong Kong isn’t like this; China is).
Remember to pack the SIM card removal tool for your phone, if applicable.
If going to a country with restricted internet access, you may want to sort out VPN access beforehand so you can still access the online services you’re used to (Facebook, YouTube, etc). Record multiple fallback IP addresses for your VPN provider as it’s hard to know which will be blocked.
7. Always have snacks and water with you
Bring water and lots of snack foods such as energy bars and nuts in your day pack to keep up your energy levels throughout the day. You never know where you might end up while exploring; it might be a long time between proper meals.
8. Find out the off-peak hours of the tourist attractions you want to visit…
…and go then to avoid crowds. Crowds are pretty much guaranteed no matter the time of day at remotely popular attractions but you can avoid the worst of it with careful planning. Again, this was a bit of surprise to someone from a country as small as N.Z. where things are pretty much guaranteed to be quiet on weekdays and mornings.
9. Get a Metro map
This is a must if you’re checking out any city with a decent metro (e.g. Guangzhou, Shanghai and Hong Kong) due to the sheer amount of time you’ll spend using it. A paper map is better (no worries about dead batteries) or download a PDF online onto your phone or tablet.
10. Invest in or borrow a decent camera
As good as phone cameras are these days, there’s still no substitute for a standalone camera.
And finally (bonus tip 11), if I’ve learned one thing about travel so far it’s this: the big-name tourist attractions at any given destination can be pretty overrated. They’re often geared towards foreigners so much so that they shield you from the actual local culture. Some of the most enjoyable experiences I’ve had travelling have been while wandering around exploring, taking it all in and spontaneously discovering things. So don’t just tick all the boxes, get out there and experience the authentic whatever-place-it-is.